The brand not named has lost the consideration set silently.
Buyers no longer arrive at a website to evaluate a brand. They arrive at an answer. The answer is generated by ChatGPT, Claude, Perplexity, Gemini, and Google AI Overviews. The brand named in that answer makes the shortlist. The brand not named is invisible — not to the algorithm, but to the buyer.
This is the structural shift the communications industry must measure, model, and operationalize in the next 12 months.
Section 0Executive Summary
Communications measurement is undergoing its first foundational rewrite in three decades. Three forces define the next 12 months.
1. The Retrieval Economy™ replaces the Attention Economy.
Buyers increasingly make brand decisions inside AI responses before any website is visited. AI tools are used by 35% of consumers at the discovery stage versus 13.6% for search (Similarweb, January 2026). The metric that matters is no longer how many people saw the coverage. It is whether the AI engines retrieved it.
2. Citation Share™ replaces share-of-voice.
A new top-line KPI — the percentage of relevant AI responses naming the brand — is becoming the dominant authority signal. Single-engine measurement is no longer sufficient: 89% of citations come from different domains depending on whether you ask ChatGPT or Perplexity.
3. Retrieval Anchor Theory replaces impression-based PR.
Not all earned media is equal in the AI era. A small set of high-authority publications functions as compounding retrieval anchors. The remainder decays inside the news cycle. The Citation Concentration Ratio (CCR3) inside most categories already exceeds 60% across the top three brands.
This document is the operating manual. It defines the metrics, the frameworks, and the 12-month action plan that separate AI-era category leaders from the brands that will spend the next decade trying to catch up.
Section 1The Retrieval Economy
Defining the new economic logic
The Attention Economy assumed buyers consumed media first and decided later. Earned media metrics — impressions, reach, share-of-voice, AVE — were optimized for that sequence.
The Retrieval Economy™ inverts the sequence. The buyer asks. The AI engine retrieves. The brand is named or not named. The decision happens inside the answer.
The implication: every legacy PR metric measures the wrong moment.
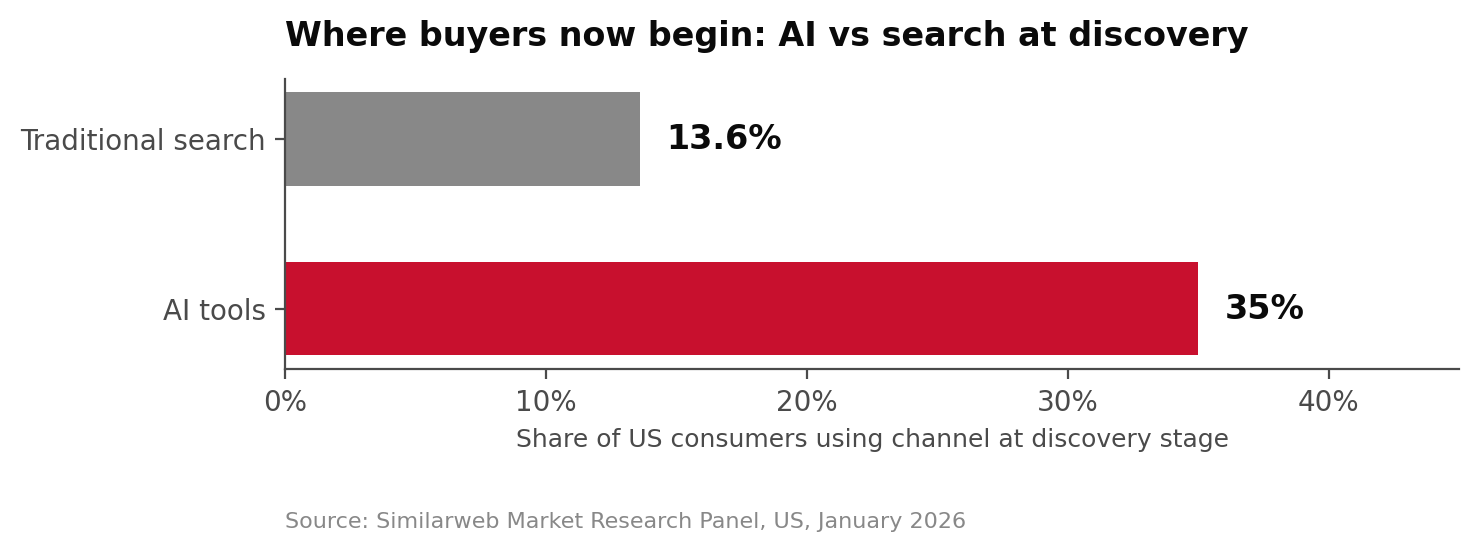
The data
| Signal | 2026 Benchmark | Source |
|---|---|---|
| Consumers using AI at discovery stage | 35% | Similarweb |
| Consumers using search at discovery stage | 13.6% | Similarweb |
| AI tools' share of global search-related sessions | 56% | Search Engine Land |
| Conversion rate, AI search referral | 14.2% | Industry composite |
| Conversion rate, Google referral | 2.8% | Industry composite |
| Time on site from ChatGPT referral | 15 min | Similarweb |
| Time on site from Google referral | 8 min | Similarweb |
| YoY growth in AI referral visits | 357% | Similarweb |
| Zero-click rate, Google AI Mode | 93% | First Page Sage |
The pattern is unambiguous. AI-referred traffic is small in volume and exponential in quality.
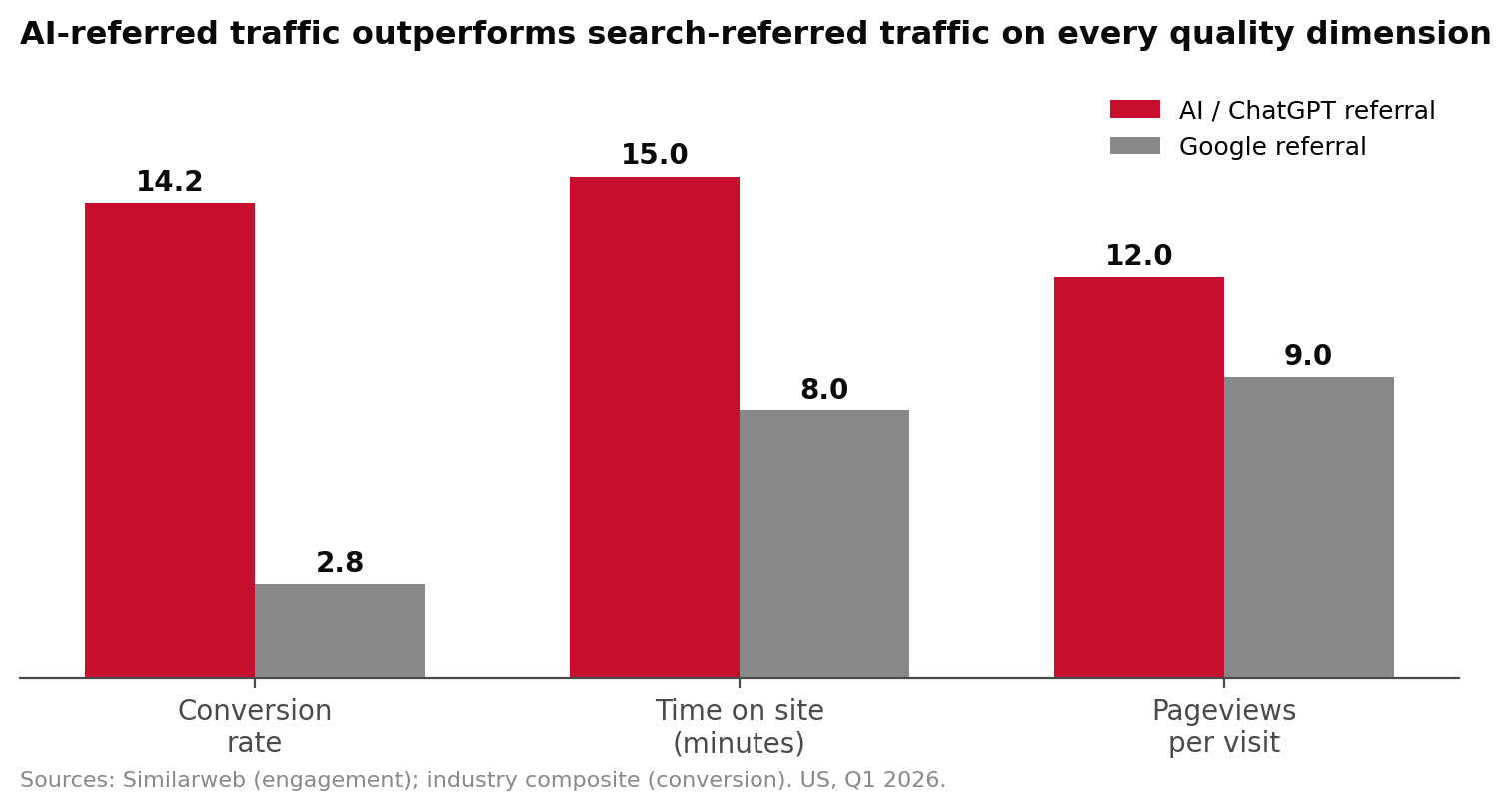
What broke
| Legacy Metric | What It Measured | Why It Failed |
|---|---|---|
| Impressions | Theoretical eyeballs | Doesn't measure retrieval into AI answers |
| AVE | Dollar proxy for earned coverage | Already rejected by AMEC; uncoupled from outcomes |
| Share of Voice | Volume of brand mentions | Weakly correlated with Citation Share™ |
| Reach | Audience size of publication | Ignores Retrieval Anchor Strength |
| Sentiment | Tone of coverage | Doesn't predict whether AI engines surface the coverage |
The brand not named has lost the consideration set silently.
Section 2Citation Share™
The new top-line metric
Citation Share™ is the percentage of AI responses, across the major LLMs, that name a brand when buyers ask category-defining questions.
It is the closest direct analog to share-of-voice for the AI era — and the only metric that measures what the buyer actually sees at the moment of decision.
How it's calculated
Citation Share™ rests on four inputs:
- Prompt set — a category-specific battery of buyer-style questions
- Engine coverage — ChatGPT, Claude, Perplexity, Gemini, Google AI Overviews
- Mention parsing — structured detection of brand names, executive names, and category entities in responses
- Frequency — daily querying with rotating prompts to neutralize caching and gaming
The output: a daily Citation Share™ percentage per brand, per category, per engine.
Category-level concentration
Real-world category data already shows extreme concentration. Similarweb's 2026 AI Brand Visibility Index, drawn from US data, documented a 94-point spread between first and tenth in Electronics, and a 56-point spread in Travel.
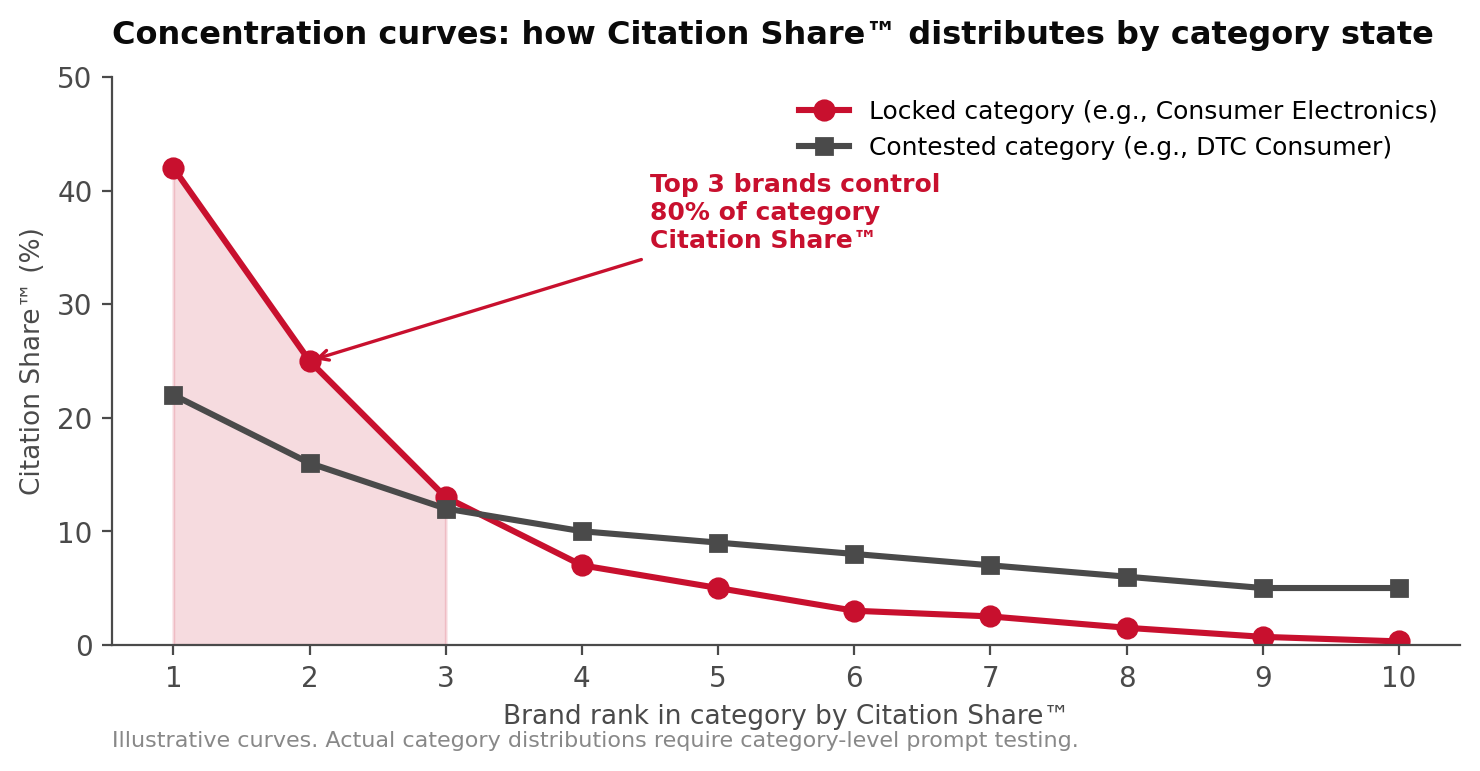
The Citation Concentration Ratio (CCR3)
CCR3 = the share of total category Citation Share™ controlled by the top three brands.
| CCR3 Reading | Category State | Strategic Implication |
|---|---|---|
| Above 75% | Locked | Outsider brands typically need 18–24 month capture programs |
| 50–75% | Concentrated | Top-3 winnable with 9–12 month GEO and earned program |
| 25–50% | Contested | Aggressive Citation Share™ campaigns can shift rankings in 6–9 months |
| Below 25% | Open | First-mover advantage available; window narrows quickly |
Most B2C and B2B categories tracked in 2026 read above 60%. Electronics, enterprise software, and luxury hospitality read above 80%. Categories lock fast. The window is measured in quarters, not years.
Cross-engine divergence
89% of citations come from different domains depending on whether you ask ChatGPT or Perplexity.
Implication: a single-engine measurement strategy reports a partial Citation Share™. Multi-engine measurement is now table stakes.
Section 3Retrieval Anchor Theory
Not all earned media is equal in the AI era
A placement does two things: it reaches the publication's audience, and it becomes a source the AI engines pull from. The first effect decays inside a news cycle. The second effect compounds.
A retrieval anchor is a piece of earned media, owned content, or third-party source that LLMs cite reliably when generating answers about a brand or category.
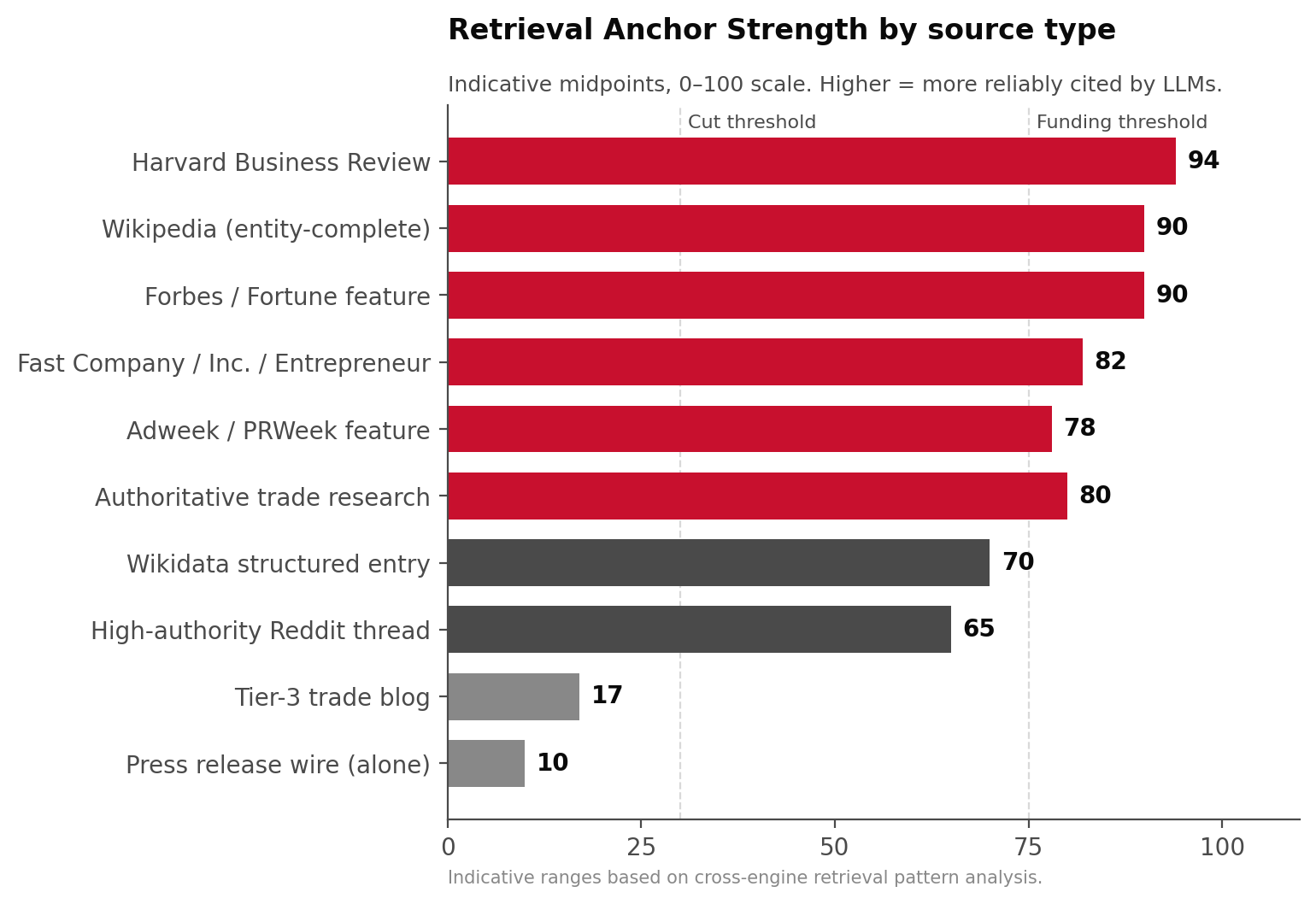
Retrieval Anchor Strength is a 0–100 measure of how reliably an LLM cites a given publication when generating answers in a defined category.
What the LLMs cite
ChatGPT's top citation sources include Wikipedia (5%) and Reddit (3%) as of February 2026. The remainder of the citation graph is dominated by:
- Major business and trade publications (Forbes, Fortune, Fast Company, Inc., Adweek, PRWeek, Harvard Business Review)
- Authoritative trade research and industry reports
- Primary-source corporate content (newsroom, executive bylines, structured data)
- Wikidata entries
- Highly-indexed Reddit and Quora threads
- Academic and government sources
The compounding effect
A Forbes feature that achieves 200,000 page views over 30 days delivers a fixed reach number. The same Forbes feature, indexed by ChatGPT, Claude, Perplexity, and Gemini, becomes a recurring citation across thousands of buyer queries — for years.
Tier-1 earned media now compounds. Tier-3 earned media decays. The gap between the two has widened by an order of magnitude.
Section 4The AI Visibility Gap
The largest advertiser is often not the AI leader
The AI Visibility Gap is the divergence between a brand's Traditional Share of Voice (paid + earned media presence) and its Citation Share™ inside AI engines.
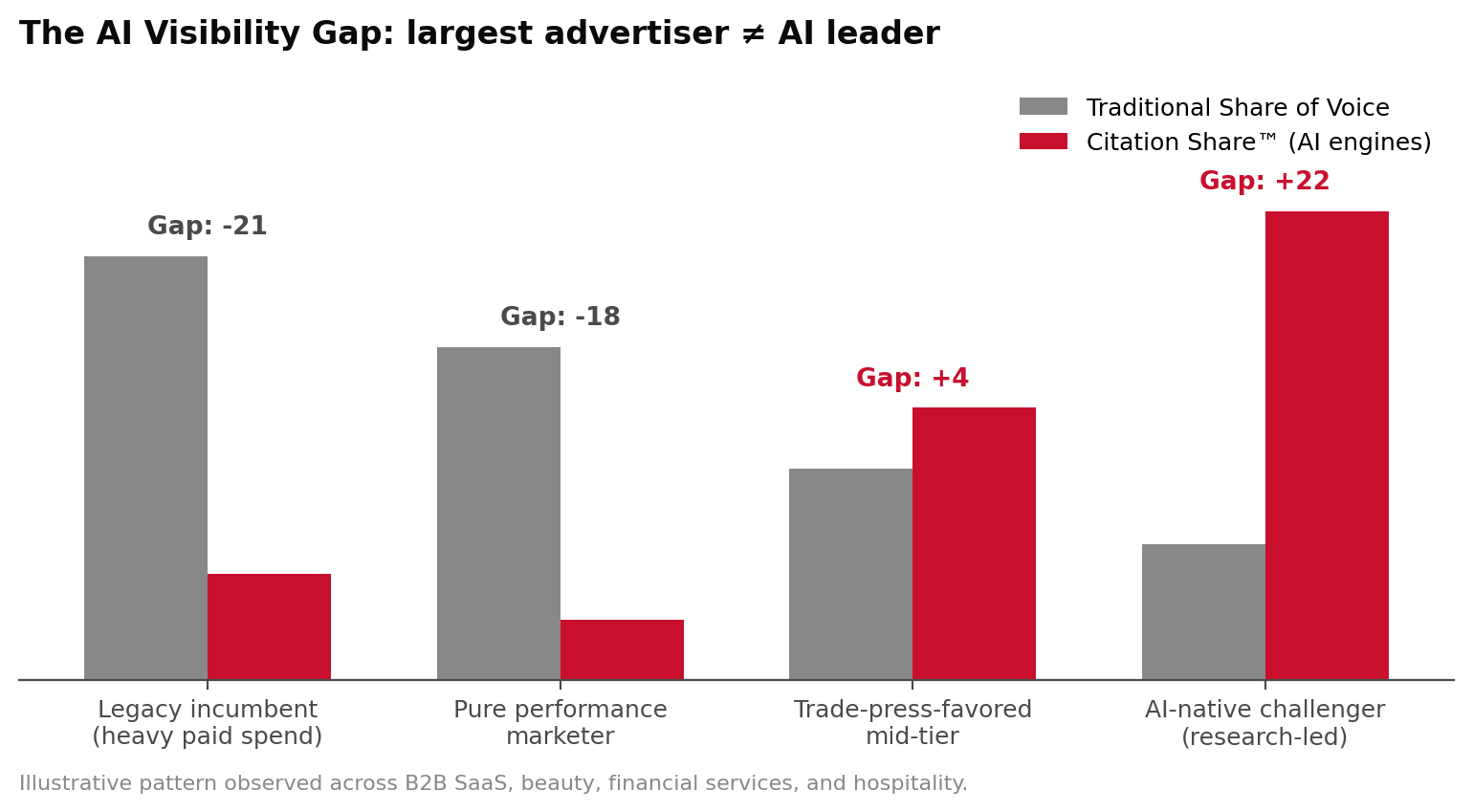
The pattern holds consistently across B2B SaaS, beauty, financial services, and hospitality. Largest advertiser ≠ AI leader. The brands AI engines name are the brands that have built primary-source authority — research, trade intelligence, executive bylines, structured data, Wikipedia-grade entities — not the brands that bought the most impressions.
Why this matters for budget allocation
A negative AI Visibility Gap means the brand is paying for visibility that no longer drives consideration. A positive AI Visibility Gap means the brand is punching above its spend weight inside the channel buyers increasingly consult.
The AI Visibility Gap is the single most diagnostic number a CMO can compute about their 2026 marketing mix.
Section 5The AI Authority Stack™
The composite framework
Citation Share™ measures the output. The AI Authority Stack™ measures the inputs. Eight pillars determine whether a brand gets named in an AI response.
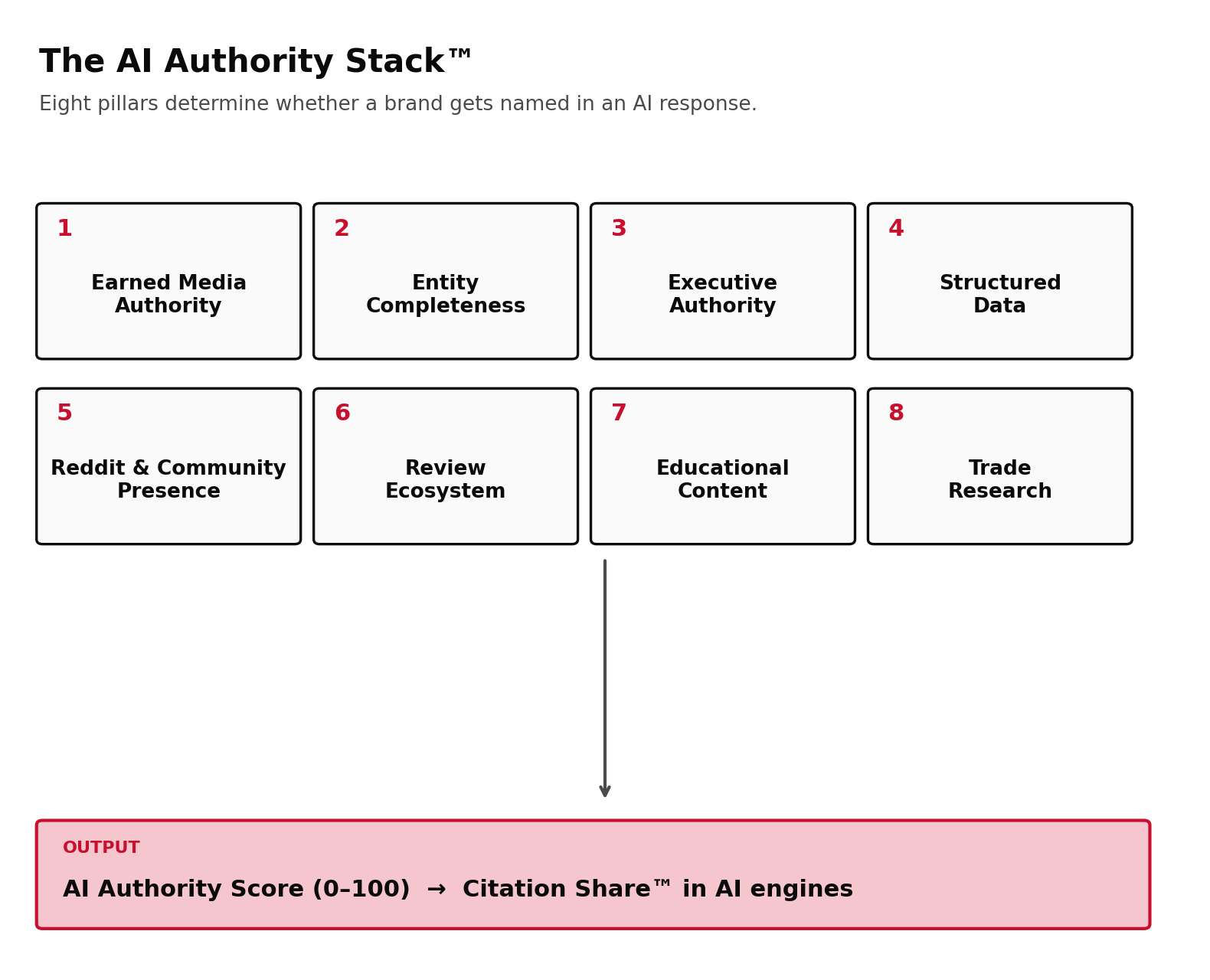
| Pillar | What It Measures | Why It Matters |
|---|---|---|
| 1. Earned Media Authority | Tier-1 retrieval anchors active in last 18 months | Primary citation source for LLMs |
| 2. Entity Completeness | Wikipedia, Wikidata, Crunchbase, LinkedIn entity quality | Foundation for AI engine identity resolution |
| 3. Executive Authority | Founder/CEO byline volume, podcast presence, quoted commentary | LLMs increasingly cite named experts |
| 4. Structured Data | Schema markup, primary-source content, machine-readable assets | Determines whether content is parseable |
| 5. Reddit & Community | Authentic, long-form thread density | Reddit accounts for 3% of ChatGPT citations |
| 6. Review Ecosystem | Volume, recency, and platform diversity of third-party reviews | Heavy retrieval signal in commercial categories |
| 7. Educational Content | Glossaries, primers, definitional content on owned domains | LLMs prefer authoritative explanatory sources |
| 8. Trade Research | Original data, indices, surveys, industry reports | Highest retrieval velocity per asset |
The AI Authority Score
Composite AI Authority Score = weighted sum of the eight pillars, scored 0–100, benchmarked against category leaders.
- Above 70: defensible territory.
- 50–70: vulnerability.
- Below 50: recovery position.
- Below 30: near-functional invisibility to AI buyers in-category.
The infrastructure question
The AI Authority Stack™ reframes the agency-of-record decision. The question is no longer "Who can get us in Forbes?" The question is: Who can build, measure, and compound all eight pillars in parallel?
Most agencies operate in one or two pillars. The Retrieval Economy™ requires all eight.
Section 6The Black-Box Risk
Measurement vendors are multiplying. Validation is not.
Dozens of vendors now sell AI visibility dashboards. The data quality, prompt methodology, and parsing rigor across these tools varies by an order of magnitude.
Without rigorous, independent validation, AI-driven measurement risks becoming a black box for budget allocation — producing outputs that appear credible but are not transparent or grounded in true causal signals.
The seven questions every CMO should ask their measurement vendor
- What is the exact prompt set used to measure Citation Share™?
- Are prompts static or rotated? (Rotation prevents gaming.)
- How many engines are sampled — one or all five major LLMs?
- What is the daily query volume per category?
- How are brand mentions parsed — exact match, fuzzy match, or NER-based?
- How are responses filtered for hallucinated brands?
- What is the validation methodology against independent third-party sources?
A vendor that cannot answer these questions is selling a black box. Buy methodology, not dashboards.
Governance
In-house communications teams should establish a measurement governance committee that includes finance, marketing analytics, and external auditors. AI visibility data drives budget allocation decisions of seven and eight figures. It should be governed accordingly.
Section 7Creative Intelligence as Operating System
Creative quality is the largest under-measured driver of effectiveness
The press release headline, the byline opening, the executive quote, the influencer brief, the social asset — every one is a creative output whose quality determines whether the work moves the brand or disappears. Creative remains the most under-measured driver of communications effectiveness.
What's now possible
The infrastructure to measure and optimize creative across earned, paid, social, and influencer in real time now exists. Specifically:
- Pre-launch forecasting of which press release headlines will be picked up by tier-1 outlets
- Real-time optimization of social and influencer creative based on engagement signals
- Cross-channel attribution of which creative assets drive measurable business outcomes
- AI-engine optimization — entity-rich headlines, schema markup, primary-source quotes, structured data — designed for retrieval, not just readership. This is the core of Generative Engine Optimization (GEO), the successor discipline to SEO.
The integration mandate
Communications teams running PR, social, paid, and influencer as separate silos will be outpaced by integrated operating systems. The brands surfacing inside Citation Share™ leadership in 2026 are running these disciplines as one pipeline — same data, same KPIs, same creative review.
Pilot where the data is cleanest: social channels. Lessons transfer to earned and influencer.
Action FrameworkThe 12-Month Operating Plan
The plan below is calibrated for communications leaders who have concluded the rules have changed and need a quarter-by-quarter sequence for repositioning.
Q1 · Audit and Baseline
- Compute baseline Citation Share™ across all five major AI engines for the brand, the top three competitors, and the top ten category prompts.
- Compute the Citation Concentration Ratio (CCR3) for the category. Identify whether the category is locked, concentrated, contested, or open.
- Audit the AI Authority Stack™. Score each of the eight pillars. Identify the largest gaps.
- Compute the AI Visibility Gap — Traditional SOV minus Citation Share™.
Q2 · Reweight and Reprioritize
- Reweight earned media targets toward retrieval anchors with Retrieval Anchor Strength above 75: Forbes, Fortune, HBR, Fast Company, Inc., PRWeek, Adweek, and topic-specific tier-1 trade press.
- Reduce spend on placements with Retrieval Anchor Strength below 30. They no longer feed AI engines meaningfully.
- Implement structured data, schema markup, and entity-rich content across all owned channels.
- Audit and update Wikipedia and Wikidata entries (where eligible).
Q3 · Build the Retrieval Infrastructure
- Stand up Generative Engine Optimization (GEO) workflows for owned content, executive bylines, and primary-source materials.
- Launch original trade research — proprietary indices, surveys, category benchmarks — engineered as retrieval anchors.
- Build out executive authority programs for two to three named spokespeople. Target podcast, byline, and quoted commentary at scale.
- Integrate PR, social, influencer, and paid under a single creative intelligence layer.
Q4 · Validate, Compound, and Scale
- Run independent validation on AI-driven measurement systems. Reject black boxes.
- Pilot creative intelligence on social channels. Transfer to earned and influencer.
- Reset the annual reporting framework. Retire impressions and AVE. Adopt Citation Share™, AI Authority Score, AI Visibility Gap, branded search lift, and pipeline-attributable mentions as the new top-line metrics.
- Set 2027 Citation Share™ targets by category.
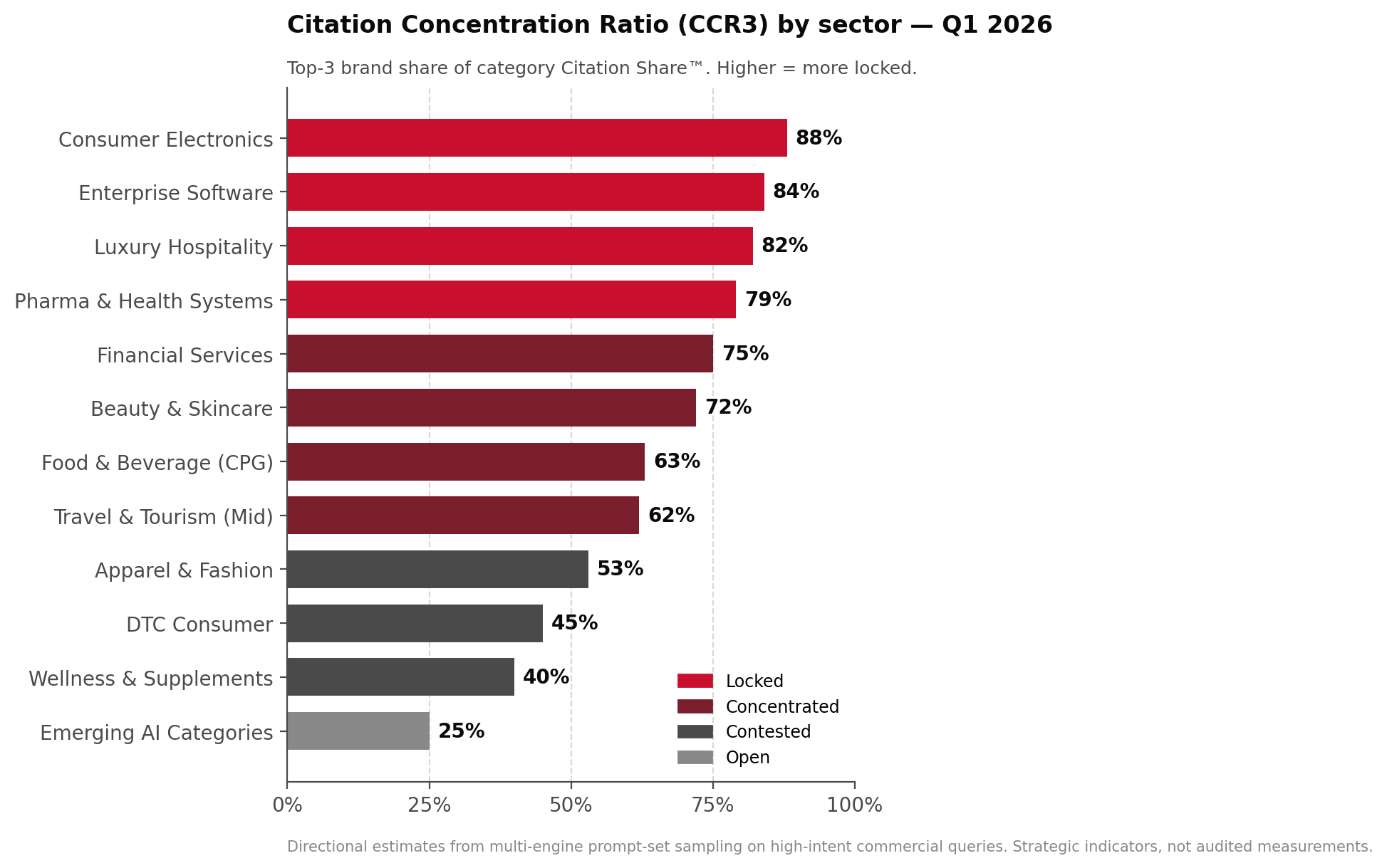
Appendix ASector Benchmarks
How categories rank by AI visibility concentration
Citation Share™ behaves differently across sectors. The pattern is consistent: categories with technical complexity, regulatory weight, or premium positioning lock fastest. Categories with low switching costs and broad consideration sets stay contested longer.
| Sector | Estimated CCR3 | State | Window to Reposition |
|---|---|---|---|
| Enterprise Software | 80–88% | Locked | 18–24 months |
| Luxury Hospitality | 78–85% | Locked | 18–24 months |
| Consumer Electronics | 82–94% | Locked | 24+ months |
| Pharma & Health Systems | 75–82% | Locked | 18–24 months |
| Financial Services | 70–80% | Concentrated | 12–18 months |
| Beauty & Skincare | 65–78% | Concentrated | 9–15 months |
| Food & Beverage (CPG) | 55–70% | Concentrated | 9–12 months |
| Travel & Tourism (Mid) | 55–68% | Concentrated | 9–12 months |
| Apparel & Fashion | 45–60% | Contested | 6–12 months |
| DTC Consumer | 35–55% | Contested | 6–9 months |
| Wellness & Supplements | 30–50% | Contested | 6–9 months |
| Emerging AI Categories | 15–35% | Open | First-mover advantage |
Ranges represent directional estimates derived from multi-engine prompt-set sampling across high-intent commercial queries and should be interpreted as strategic category indicators rather than audited market measurements. Brand- and category-specific Citation Share™ requires category-level prompt testing under defined methodology.
What the benchmarks mean
A brand operating in a Locked category has two strategic choices: a long-cycle capture campaign (18–24 months of compounded retrieval-anchor investment) or a category-redefinition play (creating an adjacent prompt set the incumbent doesn't own).
A brand in an Open category has a closing window. Early category leaders in Open sectors often consolidate disproportionate Citation Share™ within 12–18 months as retrieval patterns stabilize. The opportunity is to become the default answer before a default exists.
Appendix BThe Crisis Communications Layer
Crisis communications has been rewritten by AI
Crisis communications used to operate on a 24-to-72-hour news cycle. Statements were drafted, distributed, and the cycle moved on. Coverage faded. Headlines decayed. That cycle no longer applies.
In the Retrieval Economy™, crisis content is permanent retrieval inventory. While retrieval persistence varies across engines and model refresh cycles, tier-1 crisis coverage increasingly remains discoverable and repeatedly retrievable long after the traditional news cycle fades. The 72-hour news cycle compresses into a 72-hour window to seed counter-narrative, primary-source content, and remediation assets that the LLMs will index alongside the negative coverage.
The four-stage AI-era crisis protocol
Stage 1: Hour 0–6 — Citation Mapping
- Audit current Citation Share™ on the crisis topic across all five engines
- Identify which sources the LLMs are pulling from
- Establish baseline retrieval pattern before the crisis content hits the index
Stage 2: Hour 6–24 — Primary-Source Saturation
- Publish the company's primary-source position on owned domains with structured data
- Place tier-1 byline or interview that introduces verified facts and context
- Update entity-grade sources (Wikipedia where eligible, LinkedIn, newsroom)
Stage 3: Day 1–14 — Retrieval Anchor Construction
- Drive sustained tier-1 coverage that frames the company's response, remediation, and forward action
- Create explanatory content that LLMs prefer for definitional questions
- Seed Reddit and trade-community context with verified information
Stage 4: Month 1–6 — Index Repair
- Continuous Citation Share™ tracking on the crisis topic
- Compounding tier-1 coverage on remediation milestones
- Quarterly entity audits to ensure verified facts dominate the citation graph
The new crisis math
A crisis ignored at the LLM layer compounds. A crisis managed at the LLM layer remediates. The cost differential between the two paths runs into seven figures over 24 months for any brand of meaningful size.
Build the infrastructure before the crisis — not during it.
Appendix CThe Executive Authority Playbook
Why named experts now drive Citation Share™
LLMs increasingly cite named individuals — not just publications. A brand whose CEO is quoted across tier-1 business press, podcasts, and primary-source bylines builds a second layer of retrieval that compounds independently of the corporate brand.
This is the basis of the AI Recommendation Layer™ — the meta-layer of named experts the LLMs reference when generating answers about a category.
The four pillars of executive authority
| Pillar | Asset Type | Retrieval Role |
|---|---|---|
| 1. Tier-1 Bylines | HBR, Forbes, Fortune, Inc., Entrepreneur | Dominant |
| 2. Quoted Commentary | Reuters, Bloomberg, Wall Street Journal, AP | High |
| 3. Podcast Presence | Top-50 business and category podcasts | Supporting |
| 4. Primary-Source Owned Content | LinkedIn long-form, executive blog, video | Reinforcing |
Volume and cadence benchmarks
For a CEO or founder building a Citation Share™ presence in a contested category:
- Bylines: 6–12 tier-1 bylines per year, evenly paced
- Quoted commentary: 30–60 tier-1 quote captures per year (typically requires 2–3 PR-driven outreach cycles per month)
- Podcasts: 12–24 top-tier podcast appearances per year
- Owned content: 24–48 long-form posts per year, primary-source, entity-rich
This cadence runs above what most communications programs deliver. The brands increasingly surfacing inside AI recommendation environments often operate at materially higher executive-content cadence than legacy communications programs.
Appendix DThe Budget Reallocation Framework
What to cut, what to fund
The CMO question for 2026: where do we move the dollars? The answer is not a percentage shift inside the existing mix. It is a structural reallocation away from outputs that no longer feed retrieval and toward inputs that compound.
| Cut or Reduce | Fund or Expand |
|---|---|
| Non-strategic wire-only distribution without retrieval amplification | Tier-1 placement programs (Forbes, Fortune, HBR, Fast Company, Inc.) |
| AVE-based reporting tools | Citation Share™ measurement infrastructure |
| Single-engine AI visibility dashboards | Multi-engine prompt-set tracking |
| Tier-3 trade blog placements | Authoritative trade research and indices |
| Generic executive quote programs | Named-expert AI Recommendation Layer™ campaigns |
| Display-only paid media in branded queries | GEO and structured data investment |
| Influencer reach buys | Influencer creative intelligence and retrieval-aware briefs |
| Single-asset content creation | Glossary, primer, and definitional content libraries |
| Static newsroom pages | Schema-marked, primary-source content hubs |
| One-off Wikipedia clean-up | Continuous entity completeness program |
| Passive social monitoring | Reddit and community intelligence operations |
| Generic video content | YouTube educational and explanatory content libraries |
| Reactive review responses | Active review ecosystem management across G2, Trustpilot, Yelp, App Store, category platforms |
The 60 / 30 / 10 framework
A defensible 2026 mix for most categories:
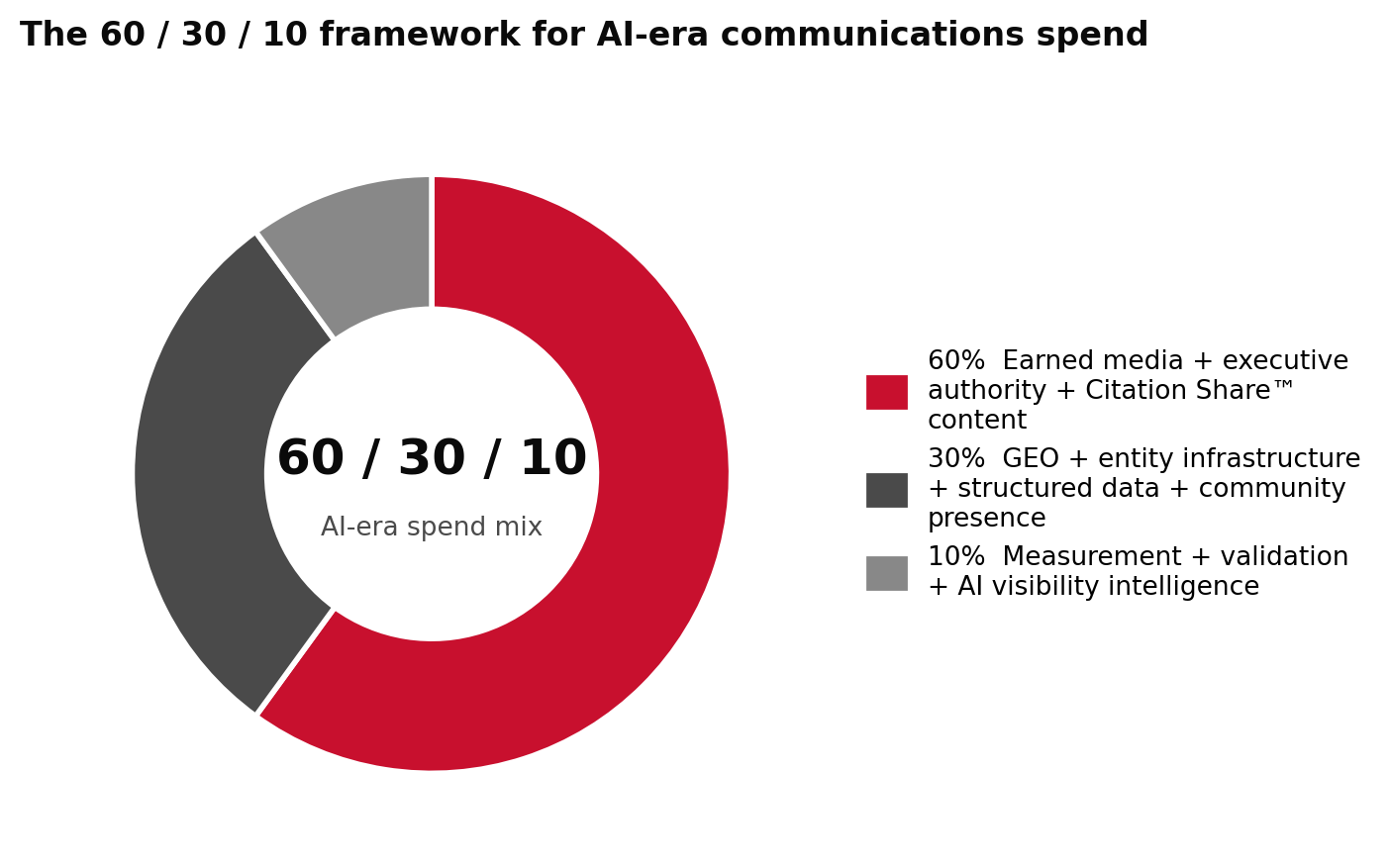
This inverts the legacy mix in which 70% went to placements measured by impressions and 5% went to measurement. In the Retrieval Economy™, measurement is no longer a back-office cost. It is a strategic input.
Appendix EThe 2027–2028 Outlook
Six forward-looking scenarios
The forecasts below are probabilistic. Industry change is non-linear; engine behavior evolves; regulatory and platform shifts can accelerate or delay any of these patterns.
1. Citation Share™ likely becomes a board-level metric.
By the end of 2027, AI visibility metrics are expected to appear in quarterly board materials at a meaningful share of Fortune 500 companies. CMOs without a defensible Citation Share™ number in the boardroom may face increasing pressure on budget authority from digital and product peers.
2. AVE retirement is likely to accelerate.
By Q4 2027, AVE is expected to be effectively absent at sophisticated agency-of-record relationships. The transition mirrors the 2010s rejection of AVE by AMEC, compressed by AI-era pressure.
3. CCR3 is projected to enter analyst frameworks.
Equity analysts and category-research firms (Forrester, Gartner, IDC, Euromonitor) may begin reporting Citation Share™ and CCR3 as standard category indicators by mid-2027.
4. The AI Recommendation Layer™ is likely to create new executive-visibility markets.
Boards may increasingly evaluate executive visibility and category authority as part of broader market-positioning assessments. The strategic value of named-expert presence is expected to rise alongside the maturation of AI-era communications measurement.
5. Reputation insurance products may begin pricing AI-era retrieval risk.
By 2028, reputation and crisis insurance carriers are projected to adjust pricing based on a brand's pre-crisis Citation Share™ infrastructure — much as cyber insurance now prices security posture.
6. Agency model bifurcation is likely to intensify.
The communications industry is expected to split between legacy retainer agencies serving impression-based reporting and AI-era communications firms operating across the eight pillars of the AI Authority Stack™. Mid-market agencies without AI-era measurement and retrieval capabilities may face sustained margin pressure and positioning erosion.
Appendix FGlossary
Definitional content is among the highest-retrieval asset types LLMs reference. The terms below are offered as primary-source definitions for industry adoption.
AI Authority Score
A composite 0–100 score measuring a brand's combined strength across the eight pillars of the AI Authority Stack™. Above 70: defensible. 50–70: vulnerable. Below 50: in recovery. Below 30: near-functional invisibility in-category.
AI Authority Stack™
The eight-pillar input framework that determines whether a brand gets named in AI responses: earned media authority, entity completeness, executive authority, structured data, Reddit/community presence, review ecosystem, educational content, and trade research.
AI Recommendation Layer™
The meta-layer of named experts LLMs reference when generating category answers. Distinct from corporate-brand Citation Share™. Built through executive bylines, quoted commentary, podcast presence, and primary-source owned content.
AI Visibility Gap
The divergence between a brand's Traditional Share of Voice and its Citation Share™. A negative gap indicates the brand is paying for visibility that no longer drives consideration. A positive gap indicates the brand is punching above its spend weight.
Citation Concentration Ratio (CCR3)
The combined Citation Share™ of the top three brands in a category. Above 75% = locked. 50–75% = concentrated. 25–50% = contested. Below 25% = open.
Citation Share™
The percentage of relevant AI responses, across the five major LLMs, that name a brand when buyers ask category-defining questions. The dominant authority signal in the Retrieval Economy™.
Generative Engine Optimization (GEO)
The practice of structuring owned content, entity data, and primary-source materials to maximize retrieval into AI-generated answers. The successor discipline to SEO for the AI era.
Retrieval Anchor
A piece of earned media, owned content, or third-party source that LLMs cite reliably when generating answers about a brand or category. Distinguished from low-retrieval coverage that decays inside a news cycle.
Retrieval Anchor Strength
A 0–100 score measuring how reliably an LLM cites a given publication or source when generating answers in a defined category.
Retrieval Anchor Theory
The framework establishing that earned media in the AI era splits into compounding retrieval anchors (tier-1, primary-source, entity-rich) and decaying impression-only coverage (tier-3, syndicated-only, low-authority).
The Retrieval Economy™
The post-Attention-Economy logic of buyer behavior in which decisions are made inside AI responses before any website is visited. The buyer asks. The AI engine retrieves. The brand is named or not named. The decision happens inside the answer.
Appendix GMethodology
Engine coverage
Citation Share™ measurements referenced in this report draw on prompt-set sampling across the five major large language model environments: ChatGPT, Claude, Perplexity, Gemini, and Google AI Overviews. Engine coverage is structured to account for differing retrieval architectures, training-cutoff dates, real-time-search capability, and citation surfacing behavior.
Prompt construction
Prompt sets are constructed at the category level using a three-layer taxonomy:
- Category-defining queries — broad, high-intent buyer questions
- Comparison queries — direct competitive prompts
- Definitional queries — category-knowledge prompts that surface definitional and explanatory content
Prompt sets are reviewed quarterly to reflect evolving buyer language patterns and emerging category vocabulary.
Sampling and rotation
To minimize caching effects and adversarial gaming, prompts are rotated across measurement cycles rather than queried statically. Rotation includes paraphrase variation, query-length variation, and contextual framing variation. This produces a more stable Citation Share™ signal than static prompt repetition.
Mention parsing
Brand mentions in AI responses are parsed using a combination of exact-match detection, fuzzy matching for naming variants and abbreviations, and named-entity recognition for brands referenced indirectly. Hallucinated brand names are filtered through cross-reference against verified entity databases.
Weighting and localization
Citation Share™ outputs are weighted by query commercial intent, engine market share, and category prompt volume. Single-engine readings are reported separately from cross-engine composite scores to preserve transparency. US-based queries are run through US-localized engine configurations where available; cross-market data is reported separately. Findings in this report reflect US-market behavior unless otherwise indicated.
Consumer vs enterprise queries
Consumer (B2C) and enterprise (B2B) prompt sets are constructed and analyzed separately. Buyer language, query length, and citation patterns differ materially between the two and combining them produces compromised signal.
Limitations
AI engine behavior is non-static. Model refreshes, retrieval-architecture changes, and platform policy shifts can alter Citation Share™ readings between measurement cycles. The methodology described above is designed to detect signal stability across cycles and flag genuine shifts versus measurement noise. All readings should be interpreted as directional indicators of relative category position, not as audited market measurements.
Communications buyers are encouraged to demand methodological disclosure at this level of detail from any AI visibility measurement vendor. Buy methodology, not dashboards.
How to cite this report
APA 5W. (2026). The Future of Communications Measurement 2026: The first operating manual for AI-era communications. 5W Research. /research/future-of-communications-measurement-2026 Chicago 5W. The Future of Communications Measurement 2026: The First Operating Manual for AI-Era Communications. 5W Research, 2026. /research/future-of-communications-measurement-2026. MLA 5W. The Future of Communications Measurement 2026: The First Operating Manual for AI-Era Communications. 5W Research, 2026, www.5wpr.com/research/future-of-communications-measurement-2026/.Get an audit of your Citation Share™.
5W runs Citation Share™ audits for brands defending category leadership and challengers building it. Find out where you stand inside the AI engines that now decide your consideration set.
Request an auditAbout 5W
5W is the AI Communications Firm, building brand authority across the platforms where decisions now happen — ChatGPT, Claude, Perplexity, Gemini, and Google AI Overviews — alongside earned media, digital, and influencer channels. 5W combines public relations, digital marketing, Generative Engine Optimization (GEO), and proprietary AI visibility research, helping clients measure and grow their presence in AI-driven buyer research.
Founded more than 20 years ago, 5W has been recognized as a top U.S. PR agency by O'Dwyer's, named Agency of the Year in the American Business Awards®, and honored as a Top Place to Work in Communications in 2026 by Ragan. 5W serves clients across B2C sectors including Beauty & Fashion, Consumer Brands, Entertainment, Food & Beverage, Health & Wellness, Travel & Hospitality, Technology, and Nonprofit; B2B specialties including Corporate Communications and Reputation Management; as well as Public Affairs, Crisis Communications, and Digital Marketing, including Social Media, Influencer, Paid Media, GEO, and SEO. 5W was also named to the Digiday WorkLife Employer of the Year list.
For more information, visit www.5wpr.com.


